

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Sebastien Ferr ´e, Univ Rennes, CNRS, Inria, IRISA Campus de Beaulieu, 35042 Rennes, France and [email protected].
Table of Links
Abstraction and Reasoning Corpus (ARC)
Object-centric Models for ARC Grids
Conclusion and Perspectives, References & Supplementary Materials
4 Object-centric Models for ARC Grids
We introduce object-centric models as a mix of patterns and functions, in contrast to DSL-based programs that are only made of functions. We examplify them with grid models that describe ARC grids in term of objects having different shapes, colors, sizes, and positions.
Such grid models are used to parse a grid, i.e. to understand its contents according to the model, and also to generate a grid, using the model as a template. A task model comprises two grid models that enable to predict an output grid, to describe a pair of grids, or to create a new pair of grids for the given task.
4.1 Mixing Patterns and Functions
The purpose of a grid model is to distinguish between invariant and variant elements across the grids of a task. In task b94a9452 (Figure 1 top), all input grids contain a square but the size, color, and position vary. This can be expressed by a pattern Square(size:?, color:?, pos:?), where Square is called a constructor (here with three arguments), and the question marks are called unknowns (similar to Prolog variables). There is also a constructor for positions as 2D vectors Vec(i:?, j:?), and primitive values for sizes (e.g., 3) and colors (e.g., blue). Patterns can be nested, like in Square(3,?,Vec(?,2)), which means “a square whose size is 3, and whose top left corner is on column 2”, in order to have models as specific as necessary. Fully grounded patterns (without unknowns) are called descriptions: e.g., Square(3,blue,Vec(2,4)).
However, with patterns only, there is no way to make the output grid depend on the input grid, which is key to solving ARC tasks. We therefore add two ingredients to grid models (typically to output models): references to the components of a grid description (typically the input one), and function applications to allow some output components to be the result of a computation. For example, in task b94a9452, the model for the small square in the output grids could be Square(!small.size, !large.color, !small.pos - !large.pos), where for instance !small.size is a reference to the size of the small square in the input grid, and ’-’ is the substraction function. This model says that “the small output square has the same size as the small input square, the same color as the large input square, and its position is the difference between the positions of the two input squares.”
Tables 1 and 2 respectively list the pattern constructors and the functions of the grid models that we have used in our experiments. Each constructor/function
Table 1: Pattern constructors by type
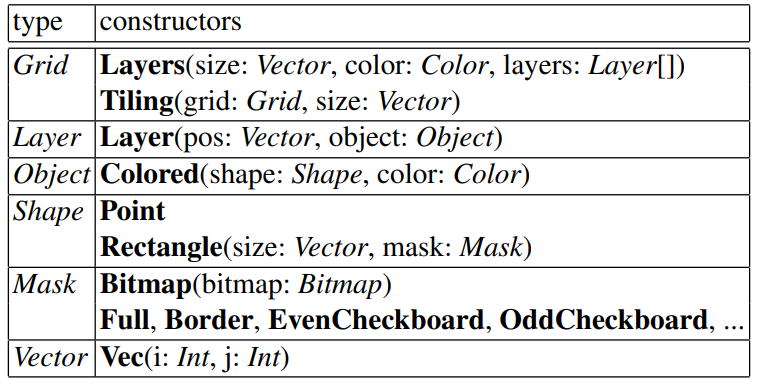
Table 2: Functions by domain

has a result type, and typed arguments. The argument types constrain which values/constructors/functions can be used in arguments. The names of constructor arguments are used to reference the components of a grid model or grid description. Grid, object and shape constructors have an implicit argument grid for their representation as a raw grid.
Point shapes have an implicit argument size, equal to Vec(1,1). Our grid models describe a grid as either a stack of layers on top of a background having some size and color, or as the tiling of a grid up to covering a grid of given size. A layer is an object at some position. An object is so far limited to a one-color shape, where a shape is either a point or some mask-specified shape fitting into a rectangle of some size. A mask is either specified by a bitmap or by one of a few common shapes such as a full rectangle or a rectangular border.
Positions and sizes are 2D integer vectors. Four primitive types are used: integers, colors, bitmaps (i.e., Boolean matrices), and grids (i.e., color matrices). The available functions essentially cover arithmetic operations on integers and on vectors, where vectors represent positions, sizes, and moves; and geometric notions such as measures (e.g., area), translations, symmetries, scaling, and periodic patterns (e.g., tiling). Unknowns are here limited to primitive types and vectors. References and functions are so far only used in output grid models. They could be used in

the input models to express constraints, e.g. to state that different objects have the same color.

4.2 Parsing and Generating Grids with a Grid Model
We introduce two operations that must be defined for any grid model M: the parsing of a grid g into a description π and the generation of a grid description π, and thus of a grid g. These operations are analogous to the parsing and generation of sentences from a grammar, where syntactic trees correspond to our descriptions π.
In both operations, the references present in the model M are first resolved using a description as the evaluation context, called environment and written ε. Concretely, each reference is a path in ε and is replaced by the sub-description at the end of this path. The functions applying to these references are then evaluated. The result is a reduced model M′ consisting only of patterns and values.
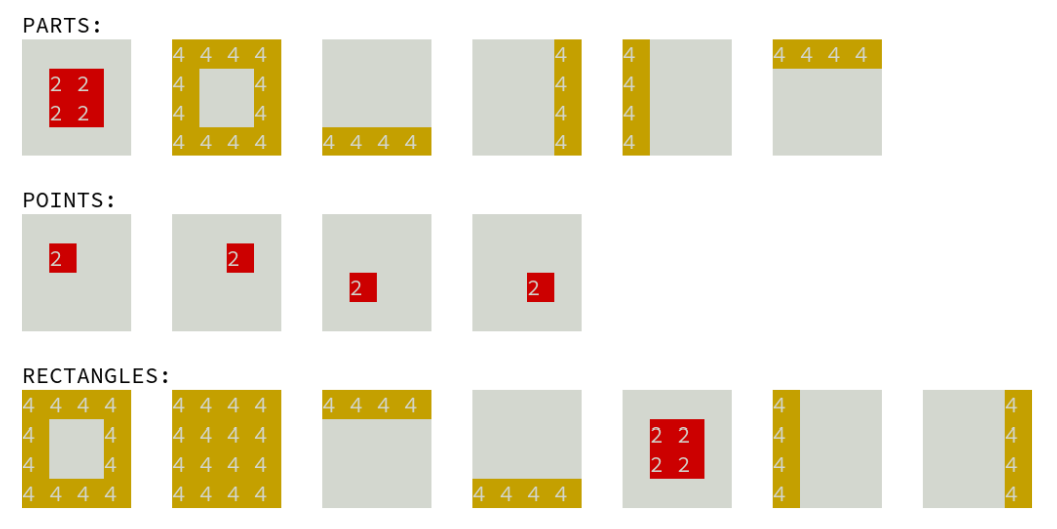
Parsing. The parsing of a grid g consists in replacing the unknowns of the reduced model M′ by descriptions corresponding to the content of the grid. It is not necessary that the whole content of the grid be described, which allows for partial models. A grid is analyzed from the top layer to the bottom layer to take into account overlapping objects. The analysis of an object is contextual, it depends on what remains to be covered in the grid after the analysis of the upper layers. For efficiency reasons, each grid is pre-processed to extract a collection of single-colored parts and the objects are parsed as unions of these parts (see Figure 3).
As the analysis of the grids can become combinatorial, we bound the number of descriptions produced by the parsing and we order them according to the description length measures defined in Section 5. As an example, the parsing of the first input grid of the running task with the model Mi of Figure 2 returns the following description: π i = Layers(Vec(12,13), black, [Layer(Vec(2,4), Colored(Rectangle(Vec(2, 2), Full), yellow), Layer(Vec(1,3), Colored(Rectangle(Vec(4,4), Full), red) ]).
Generation. The generation of a grid consists in replacing the remaining unknowns in the reduced model M′ by random descriptions of the right type, in order to obtain
a grid description, which can then be converted into a concrete grid. For example, the output model Mo of Figure 2 applied with, as environment ε, the above description π i of the first input grid generates the following description π o = Layers(Vec(4,4), yellow, [Layer(Vec(1,1), Colored(Rectangle(Vec(2,2), Full), red)]). This description conforms to the expected output grid.
An important point is that these two operations are multi-valued, i.e. may return multiple descriptions. Indeed, there are often several ways of parsing a grid according to a model, for example if the the model mentions a single object while the grid contains several ones. There are also several grids that can be generated by a model when it contains unknowns.
4.3 Predict, Describe, and Create with Task Models
We demonstrate the versatility of task models by showing that they can be used in three different modes: to predict the output grid from the input grid, to describe a pair of grids jointly, or to create a new pair of grids for the task. We use below the notation ρ, π ∈ parse(M, ε, g) to say that π is the ρ-th parsing of the grid g according to the model M and with the environment ε; and the notation ρ, π, g ∈ generate(M, ε) to say that π is the ρ-th description generated by the model M with the environment ε, and that g is the concrete grid described by π. The rank ρ is motivated by the fact that parsing and generation are multi-valued.
The predict mode is used after a model has been learned, in the evaluation phase with test cases, by predicting an output grid for the given input grid. It consists in first parsing the input grid with the input model and the nil environment in order to get an input description π i , and then to generate the output grid by using the ouput model and the input grid description as the environment.
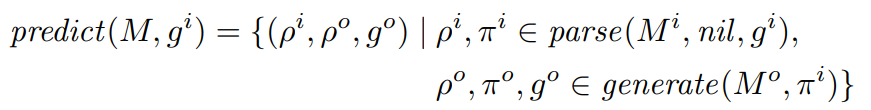
The describe mode is used in the learning phase of the model (see Section 5). It allows to obtain a joint description of a pair of grids. It consists in the parsing of the input grid and the output grid. Let us note that the parsing of the output grid depends on the result of the parsing of the input grid, hence the term ”joint description”.
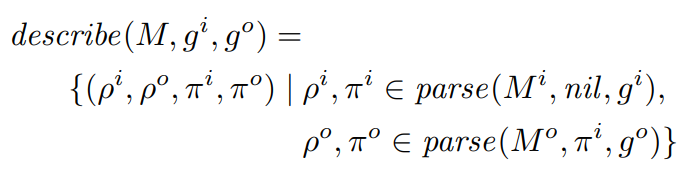
The create mode makes it possible to create a new example of the task. It consists of the successive generation of an input grid and an output grid, the latter being conditioned by the former. This mode is not used in the ARC challenge but it could contribute to the measurement of the intelligence of a system. Indeed, if an agent has really understood a task, it should be able to produce new examples5 .
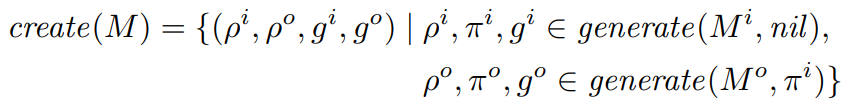
In all modes, the nil environment is used with the input model because the input grid comes first, without any prior information. Note also that all modes inherit the multi-valued property of parsing and generation. These three modes highlight an essential difference between our object-centric models and the DSL-based programs of existing approaches.
The latter are designed for prediction (computation of the output as a function of the input), they do not provide a description of the grids, nor a way to create new input grids. A new example could be created by randomly generating an input grid and applying the program, but in general, it would not respect most of the task invariants: e.g., a random bitmap would be generated rather than a solid square.
This paper is available on Arxiv under CC 4.0 license.