

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Sebastien Ferr ´e, Univ Rennes, CNRS, Inria, IRISA Campus de Beaulieu, 35042 Rennes, France and [email protected].
Table of Links
Abstraction and Reasoning Corpus (ARC)
Object-centric Models for ARC Grids
Conclusion and Perspectives, References & Supplementary Materials
5 MDL-based Model Learning
MDL-based learning works by searching for the model that compresses the data the more. The data to be compressed is here the set of training examples. We have to define two things: (1) the description lengths of models and examples, and (2) the search space of models and the learning strategy.
5.1 Description Lengths
A common approach in MDL is to define the overall description length (DL) as the sum of two parts (two-parts MDL): the model M, and the data D encoded according to the model [12].
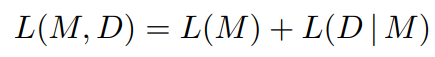
In our case, the model is a task model composed of two grid models, and the data is the set of training examples (pairs of grids). To compensate for the small number of examples, and to allow for sufficiently complex models, we use a rehearsal factor α ≥ 1, like if each example were seen α times.
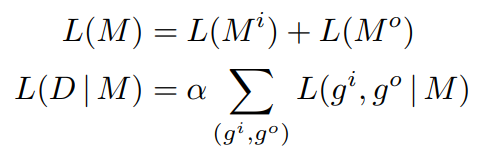
The DL of an example is based on the most compressive joint description of the pair of grids.
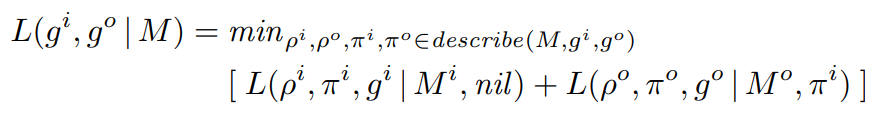
Terms of the form L(ρ, π, g | M, ε) denote the DL of a grid g encoded according to a grid model M and an environment ε, via the ρ-th description π resulting from the parsing, which serves as an intermediate representation. We can decompose these terms by using π as an intermediate representation of the grid.
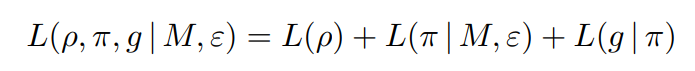
The term L(ρ) := LN(ρ) − LN(1) encodes the extra-cost of not choosing the first parsed description, penalizing higher ranks. LN(n) is a classical universal encoding for integers [7]. The term L(π | M, ε) measures the amount of information that must be added to the model and the environment to encode the description, typically the values of the unknowns. The term L(g | π) measures the differences between the original grid and the grid produced by the description. A correct model is obtained when ρ i = 1 and L(ρ o , πo , go | Mo , πi ) = 0 for all examples, i.e. when using the first description for each input grid, there is nothing left to code for the output grids, and therefore the output grids can be perfectly predicted from the input grids.
Three elementary model-dependent DLs have to be defined:
– L(M): DL of a grid model;
– L(π | M, ε): DL of a grid description, according to the model and environment used for parsing it;
– L(g | π): DL of a grid, relative to a grid description, i.e. the errors commited by the description w.r.t. the grid.
We sketch those definitions for the grid models defined in Section 4. We recall that decription lengths are generally derived from probability distributions with the equation L(x) = − log P(x), corresponding to an optimal coding [12].
Defining L(M) amounts to encode a syntax tree with constructors, values, unknowns, references, and functions as nodes. Because of types, only a subset of those are actually possible at each node: e.g. type Layer has only one constructor. We use uniform distributions across possible nodes, and universal encoding for non-bounded ints. A reference is encoded according to a uniform distribution across all components
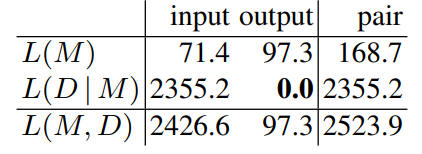
Table 3: Decomposition of L(M, D) for the model in Figure 2
of the environment that have a compatible type. We give unknowns a lower probability than constructors, and references/functions a higher probability, in order to encourage models that are more specific, and that make the output depend on the input.
Defining L(π | M, ε) amounts to encode the description components that are unknowns in the model. As those description components are actually grounded model components, the above definitions for L(M) can be reused, only adjusting the probability distributions to exclude unknowns, references and functions.
Defining L(g | π) amounts to encode which cells in grid g are wrongly specified by description π. For comparability with grid models and descriptions, we represent each differing cell as a point object – Layer(Vec(i,j),Colored(Point,c)) – and encode it like descriptions. We also have to encode the number of differing cells.
Table 3 shows the decomposition of the description length L(M, D), for the model in Figure 2 on task b94a9452, between the input and the output, and between the model and the data encoded with the model. Remind that L(D | M) is for α = 10 copies of each example. It shows that the DL of the output grids is zero bits, which means that they are entirely determined by the grid models and the input grids. The proposed model is therefore a solution to the task. The average DL of an input grid is 2355.2/10/3 = 78.5 bits, on a par with the DL of the input grid model.
5.2 Search Space and Strategy
The search space for models is characterized by: (1) an initial model, and (2) a refinement operator that returns a list of model refinements M1 . . . Mn given a model M. A refinement can insert a new component, replace an unknown by a pattern (introducing new unknowns for the constructor arguments), or replace a model component by an expression (a composition of references, values, and functions). The refinement operator has access to the joint descriptions, so it can be guided by them.
Similarly to previous MDL-based approaches [22], we adopt a greedy search strategy based on the description length of models. At each step, starting with the initial model, the refinement that reduces the more L(M, D) is selected. The search stops when no model refinement reduces it. To compensate for the fact that the input and output grids may have very different sizes, we actually use a normalized description length Lˆ that gives the same weight to the input and output components of the global DL, relative to the initial model.
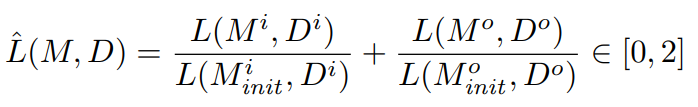
Our initial model uses the unknown grid ? for both input and output: Minit = (?, ?). The available refinements are the following:
Table 4: Learning trace for task b94a9452 (in.lay[1] is inserted before in.lay[0] because we use the final layer indices for clarity). in/out denotes the input/output model, Lˆ is the normalized DL.

– the insertion of a new layer in the list of layers – one of Layer(?,Col.(Point,?)), Layer(?,Col.(Rectangle(?,?),?)), Layer(?,!object), and !layer – where !object (resp. !layer) is a reference to an input object (resp. an input layer);
– the replacement of an unknown at path p by a pattern P when for each example, there is a parsed description π s.t. π.p matches P;
– the replacement of a model component at path p by an expression e when for each example, there is a description π s.t. π.p = e.
Table 4 shows the learning trace for task b94a9452, showing at each step the refinement that was found the most compressive. It reveals how the system learns about the task (steps are given in brackets): “The input and output grids are made of layers of objects over a background (1-2). There is a rectangle lay[1] in the input (3) and a rectangle lay[0] in the output (4). The output grid is the size of lay[1] in input (5). There is another rectangle lay[0] in the input, above lay[1] (6). We can use its color for the background of the output (8). The output rectangle is the same as the input rectangle lay[0] but with the color of lay[1] (7), and its position is equal to the difference between the positions of the two input rectangles (9). All rectangles are full (10-11) and the input background is black (12).’’
5.3 Pruning Phase
The learned model sometimes lacks generality, and fails on test examples. This is because the goal of MDL-based learning as defined above is to find the most compressive task model on pairs of grids. This is relevant for the description mode, as well as for the creation mode. However, in the prediction mode, the input grid model is used as a pattern to match the input grid, and it should be as general as possible provided that it captures the correct information for generating the output grid. For example, if all input grids in training examples have height 10, then the model will fail on a test example where the input grid has height 12, even if that height does not matter at all for generating the output.
We therefore add a pruning phase as a post-processing of the learned model. The principle is to start from this learned model, and to repeatdly apply inverse refinements while this does not break correct predictions. Inverse refinements can remove a layer or replace a constructor/value by an unknown. In order to have a uniform learning strategy, we also use here an MDL-based strategy, only adapting the description length to the prediction mode. In prediction mode, the input grid is given, and we therefore replace L(g i , go | M) by L(g o | M, gi ). Hence, the DL L(ρ i , πi , gi | Mi , nil) becomes L(ρ i , πi , gi | Mi , nil, gi ), which is equal to L(ρ i ) because π i is fully determined by the input grid, the input grid model, and the parsing rank.
This new definition makes it possible to simplify the input model while decreasing the DL. Indeed, such simplifications typically reduce L(Mi ) but increase L(π i |Mi , nil) and L(g i |π i ). The two latter terms are no more counted in the prediction-oriented measure. The cost related to ρ i is important because choosing the wrong description of the input grid almost invariably lead to a wrong predicted output grid. The DL L(ρ o , πo , go | Mo , πi ) becomes L(ρ o , πo , go | Mo , πi , gi ), which is equal to the former as π i is an abstract representation of g i . Indeed, unlike for input grids, it is important to keep output grids as compressed as possible.
On task b94a9452, starting from the model in Figure 2, the pruning phase performs three generalization steps, replacing by unknowns: the Full mask of the two input rectangles, and the black color of the input background. Those generalizations happen not to be necessary on the test examples of the task in ARC, but they make the model work on input grids that would break invariants of training examples, e.g. a cross above a rectangle above a blue background.
This paper is available on Arxiv under CC 4.0 license.