

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Sebastien Ferr ´e, Univ Rennes, CNRS, Inria, IRISA Campus de Beaulieu, 35042 Rennes, France and [email protected].
Table of Links
Abstraction and Reasoning Corpus (ARC)
Object-centric Models for ARC Grids
Conclusion and Perspectives, References & Supplementary Materials
Abstract.
The Abstraction and Reasoning Corpus (ARC) is a challenging benchmark, introduced to foster AI research towards human-level intelligence. It is a collection of unique tasks about generating colored grids, specified by a few examples only. In contrast to the transformation-based programs of existing work, we introduce object-centric models that are in line with the natural programs produced by humans. Our models can not only perform predictions, but also provide joint descriptions for input/output pairs. The Minimum Description Length (MDL) principle is used to efficiently search the large model space. A diverse range of tasks are solved, and the learned models are similar to the natural programs. We demonstrate the generality of our approach by applying it to a different domain.
1 Introduction
Artificial Intelligence (AI) has made impressive progress in the past decade at specific tasks, sometimes achieving super-human performance: e.g., image recognition [15], board games [21], natural language processing [6]. However, AI still misses the generality and flexibility of human intelligence to adapt to novel tasks with little training.
To foster AI research beyond narrow generalization [11], F. Chollet [4,5] introduced a measure of intelligence that values skill-acquisition efficiency over skill performance , i.e. the amount of prior knowledge and experience that an agent needs to reach a reasonably good level at a range of tasks (e.g., board games) matters more than its absolute performance at any specific task (e.g., chess). Chollet also introduced the Abstraction and Reasoning Corpus (ARC) benchmark in the form of a psychometric test to measure and compare the intelligence of humans and machines alike.
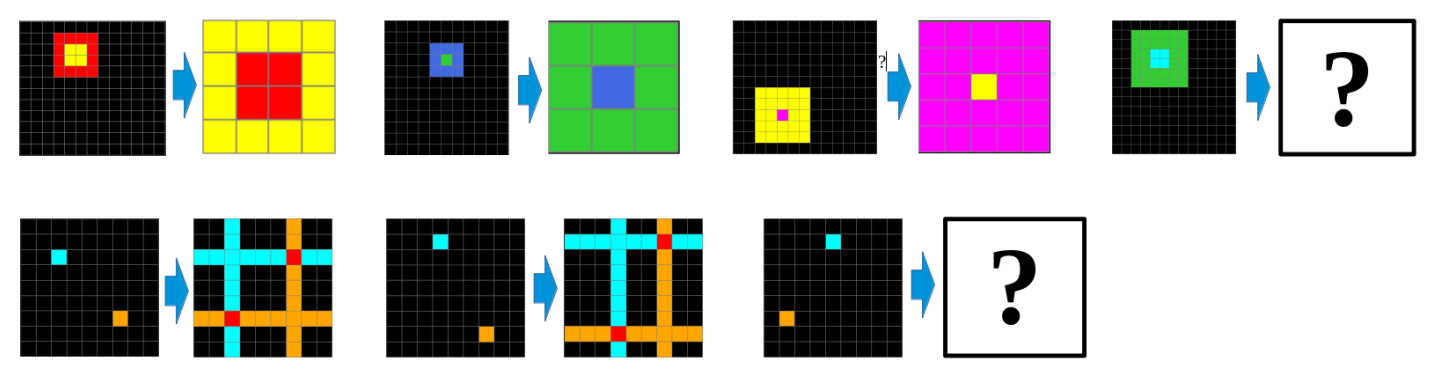
ARC is a collection of tasks that consist in learning how to transform an input colored grid into an output colored grid, given only a few examples. It is a very challenging benchmark. While humans can solve more than 80% of the tasks [14], the winner of a Kaggle contest 1 could only solve 20% of the tasks (with a lot of hard-coded primitives and brute-force search), and the winner of the more recent ARCathon’22 contest 2 could only solve 6% of the tasks.
The existing published approaches [10,3,23,2], and also the Kaggle winner, tackle the ARC challenge as a program synthesis problem, where a program is a composition of primitive transformations, and learning is done by searching the large program space. In contrast, psychological studies have shown that the natural programs produced by humans to solve ARC tasks are object-centric, and more declarative than procedural [14,1]. When asked to verbalize instructions on how to solve a task, participants typically first describe what to expect in the input grid, and then how to generate the output grid based on the elements found in the input grid.
We make two contributions w.r.t. existing work:
1. object-centric models that enable to both parse and generate grids in terms of object patterns and computations on those objects;
2. an efficient search of object-centric models based on the Minimum Description Length (MDL) principle [20].
A model for an ARC task combines two grid models, one for the input grid, and another for the output grid. This closely matches the structure of natural programs. Compared to the transformation-based programs that can only predict an output grid from an input grid, our models can also provide a joint description for a pair of grids. They can also create new pairs of grids, although this is not evaluated in this paper. They could also in principle be adapted to tasks based on a single grid or on sequences of grids. All of this is possible because grid models can be used both for parsing a grid and for generating a grid.
The MDL principle comes from information theory, and says that “the model that best describes the data is the model that compress them the more” [20,12]. It has for instance been applied to pattern mining [22,9]. The MDL principle is used at two levels: (a) to choose the best parses of a grid according to a grid model, and (b) to efficiently search the large model space by incrementally building more and more accurate models. MDL at level (a) is essential because the segmentation of a grid into objects is taskdependent and has to be learned along with the definition of the output objects as a function of the input objects. The two contributions support each other because existing search strategies could not handle the large number of elementary components of our grid models, and because the transformation-based programs are not suitable to the incremental evaluation required by MDL-based search.
We report promising results based on grid models that are still far from covering all knowledge priors assumed by ARC. Correct models are found for 96/400 varied training tasks with a 60s time budget. Many of those are similar to the natural programs produced by humans. Moreover, we demonstrate the generality of our approach by applying it to the automatic filling of spreadsheet columns [13], where inputs and outputs are rows of strings instead of grids.
The paper is organized as follows. Section 2 presents the ARC benchmark, and a running example task. Section 3 discusses related work. Section 4 defines our objectcentric models, and Section 5 explains how to learn them with the MDL principle. Section 6 reports on experimental results, comparing with existing approaches.
This paper is available on Arxiv under CC 4.0 license.